tl;dr; I see no reason worth switching to Msgpack instead of good old JSON.
I was curious, how much more efficient is Msgpack at packing a bunch of data into a file I can emit from a web service.
In this experiment I take a massive JSON file that is used in a single-page-app I worked on. If I download the file locally as a .json file, the file is 2.1MB.
Converting it to Msgpack:
>>> import json, msgpack
>>> with open('events.json') as f:
... events=json.load(f)
...
>>> len(events)
3
>>> events.keys()
dict_keys(['max_modified', 'events', 'urls'])
>>> with open('events.msgpack', 'wb') as f:
... f.write(msgpack.packb(events))
...
1880266
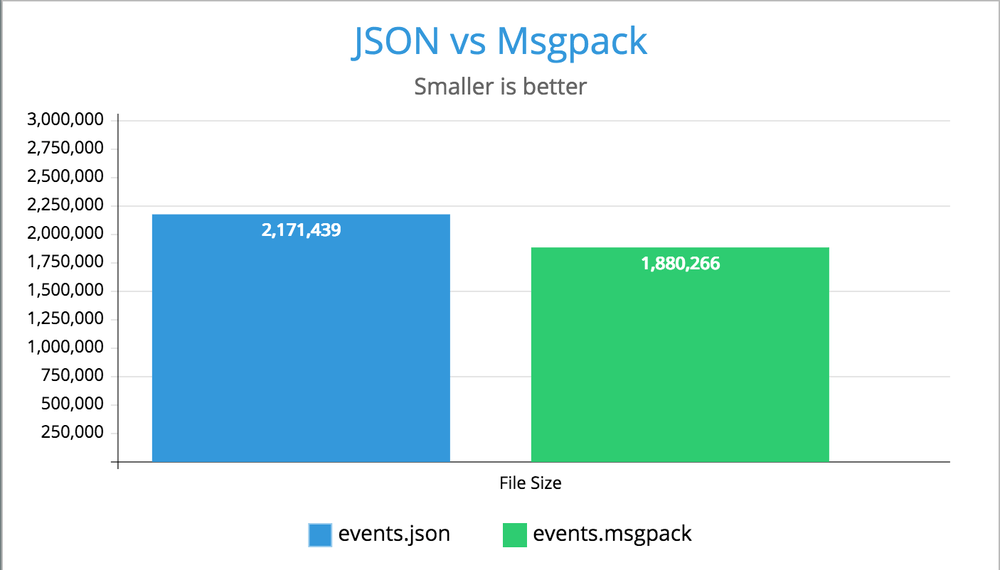
Now, let's compared the two file formats, as seen on disk:
▶ ls -lh events* -rw-r--r-- 1 peterbe wheel 2.1M Dec 19 10:16 events.json -rw-r--r-- 1 peterbe wheel 1.8M Dec 19 10:19 events.msgpack
But! How well does it compress?
More common than not your web server can return content encoded in Gzip as content-encoding: gzip. So, let's compare that:
▶ gzip events.json ; gzip events.msgpack ▶ ls -l events* -rw-r--r-- 1 peterbe wheel 304416 Dec 19 10:16 events.json.gz -rw-r--r-- 1 peterbe wheel 305905 Dec 19 10:19 events.msgpack.gz
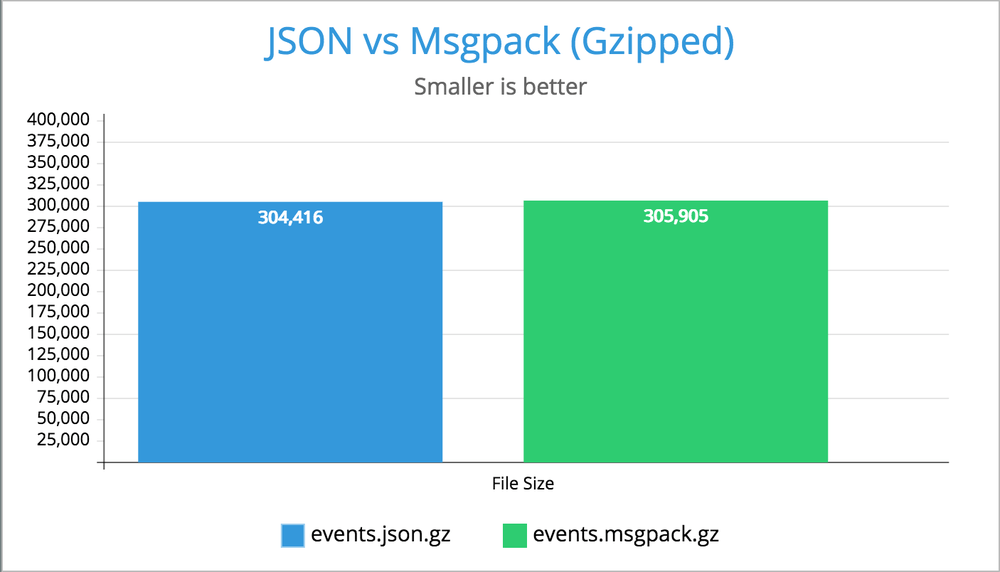
Oh my! When you gzip the files the .json file ultimately becomes smaller. By a whopping 0.5%!
What about speed?
First let's open the files a bunch of times and see how long it takes to unpack:
def f1():
with open('events.json') as f:
s = f.read()
t0 = time.time()
events = json.loads(s)
t1 = time.time()
assert len(events['events']) == 4365
return t1 - t0
def f2():
with open('events.msgpack', 'rb') as f:
s = f.read()
t0 = time.time()
events = msgpack.unpackb(s, encoding='utf-8')
t1 = time.time()
assert len(events['events']) == 4365
return t1 - t0
def f3():
with open('events.json') as f:
s = f.read()
t0 = time.time()
events = ujson.loads(s)
t1 = time.time()
assert len(events['events']) == 4365
return t1 - t0
(Note that the timing is around the json.loads() etc without measuring how long it takes to get the files to strings)
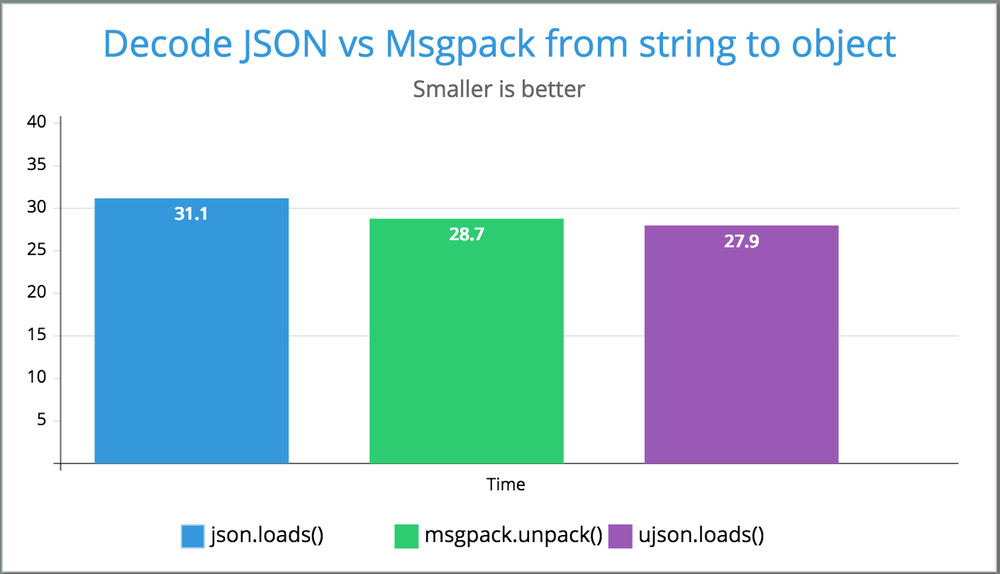
Result (using Python 3.6.1): All about the same.
FUNCTION: f1 Used 56 times
MEDIAN 30.509352684020996
MEAN 31.09178798539298
STDEV 3.5620914333233595
FUNCTION: f2 Used 68 times
MEDIAN 27.882099151611328
MEAN 28.704492484821994
STDEV 3.353800228776872
FUNCTION: f3 Used 76 times
MEDIAN 27.746915817260742
MEAN 27.920340236864593
STDEV 2.21554251130519
Same benchmark using PyPy 3.5.3, but skipping the f3() which uses ujson:
FUNCTION: f1 Used 99 times
MEDIAN 20.905017852783203
MEAN 22.13949386519615
STDEV 5.142071370453135
FUNCTION: f2 Used 101 times
MEDIAN 36.96393966674805
MEAN 40.54664857316725
STDEV 17.833577642246738
Dicussion and conclusion
One of the benefits of Msgpack is that it can used for streaming. "Streaming unpacking" as they call it. But, to be honest, I've never used it. That can useful when you have structured data trickling in and you don't want to wait for it all before using the data.
Another cool feature Msgpack has is ability to encode custom types. E.g. datetime.datetime. Like bson can do. With JSON you have to, for datetime objects do string conversions back and forth and the formats are never perfectly predictable so you kinda have to control both ends.
But beyond some feature differences, it seems that JSON compressed just as well as Msgpack when Gzipped. And unlike Msgpack JSON is not binary so it's easy to poke around with any tool. And decompressing JSON is just as fast. Almost. But if you need to squeeze out a couple of extra free milliseconds from your JSON files you can use ujson.
Conclusion; JSON is fine. It's bigger but if you're going to Gzip anyway, it's just as small as Msgpack.
Bonus! BSON
Another binary encoding format that supports custom types is BSON. This one is a pure Python implementation. BSON is used by MongoDB but this bson module is not what PyMongo uses.
Size comparison:
▶ ls -l events*son -rw-r--r-- 1 peterbe wheel 2315798 Dec 19 11:07 events.bson -rw-r--r-- 1 peterbe wheel 2171439 Dec 19 10:16 events.json
So it's 7% larger than JSON uncompressed.
▶ ls -l events*son.gz -rw-r--r-- 1 peterbe wheel 341595 Dec 19 11:07 events.bson.gz -rw-r--r-- 1 peterbe wheel 304416 Dec 19 10:16 events.json.gz
Meaning it's 12% fatter than JSON when Gzipped.
Doing a quick benchmark with this:
def f4():
with open('events.bson', 'rb') as f:
s = f.read()
t0 = time.time()
events = bson.loads(s)
t1 = time.time()
assert len(events['events']) == 4365
return t1 - t0
Compared to the original f1() function:
FUNCTION: f1 Used 106 times
MEDIAN 29.58393096923828
MEAN 30.289863640407347
STDEV 3.4766612593557173
FUNCTION: f4 Used 94 times
MEDIAN 231.00042343139648
MEAN 231.40889786659403
STDEV 8.947746458066405
In other words, bson is about 600% slower than json.
This blog post was supposed to be about how well the individual formats size up against each other on disk but it certainly would be interesting to do a speed benchmark comparing Msgpack and JSON (and maybe BSON) where you have a bunch of datetimes or decimal.Decimal objects and see if the difference is favoring the binary formats.
Comments
Post your own commentWhat's wrong with XML? Actually definable data types and such.
You can define types in JSON too if really want to. XML and JSON is just one big string after all. It's all down to you how to de-serialize it. JSON has some built in "standards", if you can call it that. With XML you have define that yourself, in some specific way to your specific tools.
With JSON, an integer makes sense between a Python and Ruby program.
Also, XML is extremely verbose.
I think BSON itself is fast, it was designed to be accessed directly, by copying it into dict you kinda misuse BSON. If for some reason you want to use standard dict to access data, then BSON is not a format to consider.
It is interesting topic to me. I want to store neural network layers and right now deciding, should I support msgpack or not. If your events.json is mostly strings, than no wonder json ≈ msgpack. It's interesting how json and msgpack compares when the data is mostly arrays of floats.
There are also MsgPack official alternative: CBOR (http://cbor.io/)
It is unfortunate that this RFC so little known ...
There are plenty of non-strings in that events.json but, yes, it's generally mostly strings.
Does it have a good Python module?
pretty good yes. It's as fast as ujson, for the same size.
Just make "pip install cbor", and you will have the high-speed implementation (with C implementation)
For another python implementations (or other languages), see more here: http://cbor.io/impls.html
i quickly performed a bench, and it gaves me these stats:
##########
*Encoding*
json -> op by sec: 86725.66920628605, (len:828)
rapidjson -> op by sec: 180454.7353457841, (len:768)
ujson -> op by sec: 190558.97336411255, (len:776)
msgpack -> op by sec: 153912.86095711155, (len:636)
cbor -> op by sec: 207190.78744576086, (len:635)
##########
*Decoding*
json -> op by sec: 91466.83280991958
rapidjson -> op by sec: 110461.44729824932
ujson -> op by sec: 129011.48500404017
msgpack -> op by sec: 243895.1547813709
cbor -> op by sec: 168211.05628806681
* same size of MsgPack
I find msgpack really shines when you design your datasets and protocols around heavy use of arrays and integers. If your data is string heavy, there is little reason to use it. Also the elephant in the room, what about large binary values? It's annoying to encode Dates in JSON, but it's really annoying to have to encode large binary values as giant base64 strings.
Have you tried the official bson module that's included in PyMongo? PyMongo's bson is implemented in C, it's surely much faster than the pure-Python module you tried.
No, because I couldn't find it outside pymongo.
When it comes to embedding images/files you get same size than gzipped json without base64 encoding, and ~30% less size than JSON uncompressed. Yes messagepack is ideal for those use cases using pure bytes which is not supported in JSON.
I did a lot of investigation around this (compared some other binary formats as well) and came to the same conclusions.
If you're interested in seeing the full data set - you can read about it here https://www.lucidchart.com/techblog/2019/12/06/json-compression-alternative-binary-formats-and-compression-methods/
I just tried MessagePack to minimise a pretty hefty web response (20,000 items, totalling 6MB).
The result was... 20MB!
After a bit of research, I've found that it's due to the nature of binary serialisers, and that JSON specific serialised can be much more efficient because they're designed to work with specifically with the JSON format.
I have since used GZip and the response is now a fantastic 600kb
So, from 6MB, to 20MB, to 600kb?
What about Brotli or Zstandard? Even smaller?
Yeah, the original response using default .NET JSON serialiser (System.Text.Json) was 6MB.
Then I had a go with MesssagePack and it was 20MB.
Then I tried GZip and got a nice 600kb.
I didn't try anything after that - 600kb is good enough for me, excellent in fact!