Page 2
Search hidden directories with ripgrep, by default
December 30, 2023
0 comments MacOSX, Linux
Do you use rg (ripgrep) all the time on the command line? Yes, so do I. An annoying problem with it is that, by default, it does not search hidden directories.
"A file or directory is considered hidden if its base name starts with a dot character (.)."
One such directory, that is very important in my git/GitHub-based projects (which is all of mine by the way) is the .github directory. So I cd into a directory and it finds nothing:
cd ~/dev/remix-peterbecom
rg actions/setup-node
# Empty! I.e. no results
It doesn't find anything because the file .github/workflows/test.yml is part of a hidden directory.
The quick solution to this is to use --hidden:
❯ rg --hidden actions/setup-node
.github/workflows/test.yml
20: uses: actions/setup-node@v4
I find it very rare that I would not want to search hidden directories. So I added this to my ~/.zshrc file:
alias rg='rg --hidden'
Now, this happens:
❯ rg actions/setup-node
.github/workflows/test.yml
20: uses: actions/setup-node@v4
With that being set, it's actually possible to "undo" the behavior. You can use --no-hidden
❯ rg --no-hidden actions/setup-node
And that can useful if there is a hidden directory that is not git ignored yet. For example .download-cache/.
fnm is much faster than nvm.
December 28, 2023
1 comment Node, MacOSX
I used nvm so that when I cd into a different repo, it would automatically load the appropriate version of node (and npm). Simply by doing cd ~/dev/remix-peterbecom, for example, it would make the node executable to become whatever the value of the optional file ~/dev/remix-peterbecom/.nvmrc's content. For example v18.19.0.
And nvm helps you install and get your hands on various versions of node to be able to switch between. Much more fine-tuned than brew install node20.
The problem with all of this is that it's horribly slow. Opening a new terminal is annoyingly slow because that triggers the entering of a directory and nvm slowly does what it does.
The solution is to ditch it and go for fnm instead. Please, if you're an nvm user, do consider making this same jump in 2024.
Installation
Running curl -fsSL https://fnm.vercel.app/install | bash basically does some brew install and figuring out what shell you have and editing your shell config. By default, it put:
export PATH="/Users/peterbe/Library/Application Support/fnm:$PATH"
eval "`fnm env`"
...into my .zshrc file. But, I later learned you need to edit the last line to:
-eval "`fnm env`"
+eval "$(fnm env --use-on-cd)"
so that it automatically activates immediately after you've cd'ed into a directory.
If you had direnv to do this, get rid of that. fmn does not need direnv.
Now, create a fresh new terminal and it should be set up, including tab completion. You can test it by typing fnm[TAB]. You'll see:
❯ fnm
alias -- Alias a version to a common name
completions -- Print shell completions to stdout
current -- Print the current Node.js version
default -- Set a version as the default version
env -- Print and set up required environment variables for fnm
exec -- Run a command within fnm context
help -- Print this message or the help of the given subcommand(s)
install -- Install a new Node.js version
list ls -- List all locally installed Node.js versions
list-remote ls-remote -- List all remote Node.js versions
unalias -- Remove an alias definition
uninstall -- Uninstall a Node.js version
use -- Change Node.js version
Usage
If you had .nvmrc files sprinkled about from before, fnm will read those. If you cd into a directory, that contains .nvmrc, whose version fnm hasn't installed, yet, you get this:
❯ cd ~/dev/GROCER/groce/
Can't find an installed Node version matching v16.14.2.
Do you want to install it? answer [y/N]:
Neat!
But if you want to set it up from scratch, go into your directory of choice, type:
fnm ls-remote
...to see what versions of node you can install. Suppose you want v20.10.0 in the current directory do these two commands:
fnm install v20.10.0
echo v20.10.0 > .node-version
That's it!
Notes
-
I prefer that
.node-versionconvention so I've been going around doingmv .nvmrc .node-versionin various projects -
fnm lsis handy to see which ones you've installed already -
Suppose you want to temporarily use a specific version, simply type
fnm use v16.20.2for example -
I heard good things about volta too but got a bit nervous when I found out it gets involved in installing packages and not just versions of
node. -
fnmdoes not concern itself with upgrading yournodeversions. To get the latest version ofnodev21.x, it's up to you to checkfnm ls-remoteand compare that with the output ofnode --version.
Comparing different efforts with WebP in Sharp
October 5, 2023
0 comments Node, JavaScript
When you, in a Node program, use sharp to convert an image buffer to a WebP buffer, you have an option of effort. The higher the number the longer it takes but the image it produces is smaller on disk.
I wanted to put some realistic numbers for this, so I wrote a benchmark, run on my Intel MacbookPro.
The benchmark
It looks like this:
async function e6() {
return await f("screenshot-1000.png", 6);
}
async function e5() {
return await f("screenshot-1000.png", 5);
}
async function e4() {
return await f("screenshot-1000.png", 4);
}
async function e3() {
return await f("screenshot-1000.png", 3);
}
async function e2() {
return await f("screenshot-1000.png", 2);
}
async function e1() {
return await f("screenshot-1000.png", 1);
}
async function e0() {
return await f("screenshot-1000.png", 0);
}
async function f(fp, effort) {
const originalBuffer = await fs.readFile(fp);
const image = sharp(originalBuffer);
const { width } = await image.metadata();
const buffer = await image.webp({ effort }).toBuffer();
return [buffer.length, width, { effort }];
}
Then, I ran each function in serial and measured how long it took. Then, do that whole thing 15 times. So, in total, each function is executed 15 times. The numbers are collected and the median (P50) is reported.
A 2000x2000 pixel PNG image
1. e0: 191ms 235KB 2. e1: 340.5ms 208KB 3. e2: 369ms 198KB 4. e3: 485.5ms 193KB 5. e4: 587ms 177KB 6. e5: 695.5ms 177KB 7. e6: 4811.5ms 142KB
What it means is that if you use {effort: 6} the conversion of a 2000x2000 PNG took 4.8 seconds but the resulting WebP buffer became 142KB instead of the least effort which made it 235 KB.
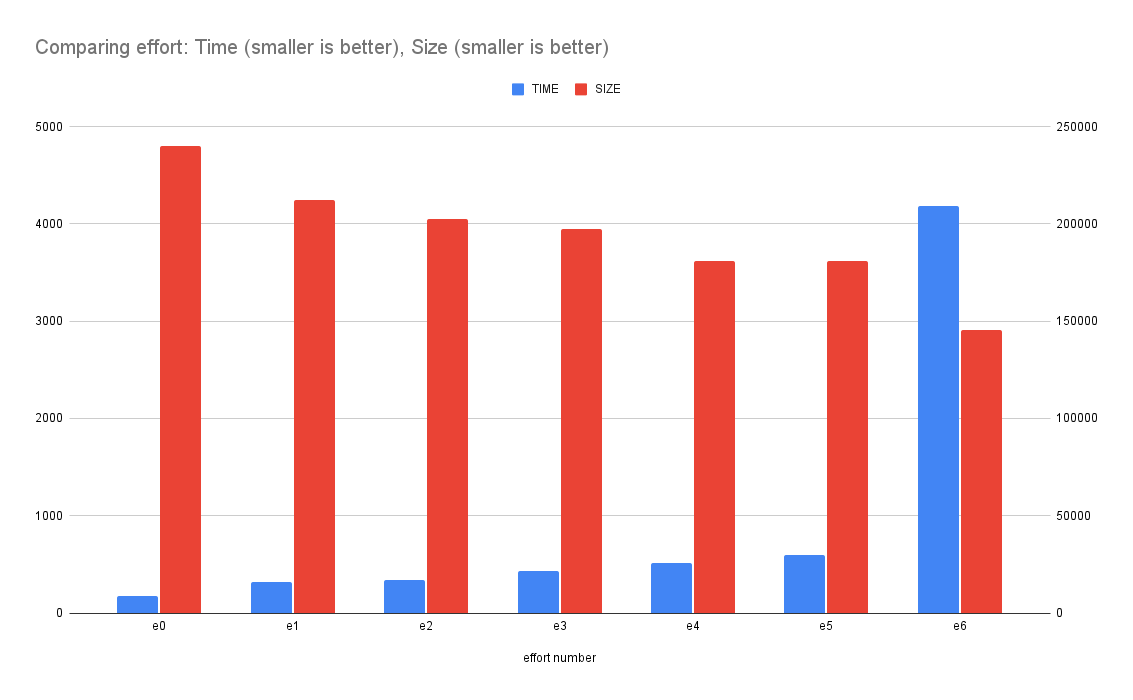
This graph demonstrates how the (blue) time goes up the more effort you put in. And how the final size (red) goes down the more effort you put in.
A 1000x1000 pixel PNG image
1. e0: 54ms 70KB 2. e1: 60ms 66KB 3. e2: 65ms 61KB 4. e3: 96ms 59KB 5. e4: 169ms 53KB 6. e5: 193ms 53KB 7. e6: 1466ms 51KB
A 500x500 pixel PNG image
1. e0: 24ms 23KB 2. e1: 26ms 21KB 3. e2: 28ms 20KB 4. e3: 37ms 19KB 5. e4: 57ms 18KB 6. e5: 66ms 18KB 7. e6: 556ms 18KB
Conclusion
Up to you but clearly, {effort: 6} is to be avoided if you're worried about it taking a huge amount of time to make the conversion.
Perhaps the takeaway is; that if you run these operations in the build step such that you don't have to ever do it again, it's worth the maximum effort. Beyond that, find a sweet spot for your particular environment and challenge.
Zipping files is appending by default - Watch out!
October 4, 2023
0 comments Linux
This is not a bug in the age-old zip Linux program. It's maybe a bug in its intuitiveness.
I have a piece of automation that downloads a zip file from a file storage cache (GitHub Actions actions/cache in this case). Then, it unpacks it, and plucks some of the files from it into another fresh new directory. Lastly, it creates a new .zip file with the same name. The same name because that way, when the process is done, it uploads the new .zip file into the file storage cache. But be careful; does it really create a new .zip file?
To demonstrate the surprise:
$ cd /tmp/
$ mkdir somefiles
$ touch somefiles/file1.txt
$ touch somefiles/file2.txt
$ zip -r somefiles.zip somefiles
adding: somefiles/ (stored 0%)
adding: somefiles/file1.txt (stored 0%)
adding: somefiles/file2.txt (stored 0%)
Now we have a somefiles.zip to work with. It has 2 files in it.
Next session. Let's say it's another day and a fresh new /tmp directory and the previous somefiles.txt has been downloaded from the first session. This time we want to create a new somefile directory but in it, only have file2.txt from before and a new file file3.txt.
$ rm -fr somefiles
$ unzip somefiles.zip
Archive: somefiles.zip
creating: somefiles/
extracting: somefiles/file1.txt
extracting: somefiles/file2.txt
$ rm somefiles/file1.txt
$ touch somefiles/file3.txt
$ zip -r somefiles.zip somefiles
updating: somefiles/ (stored 0%)
updating: somefiles/file2.txt (stored 0%)
adding: somefiles/file3.txt (stored 0%)
And here comes the surprise, let's peek into the newly zipped up somefiles.txt (which was made from the somefiles/ directory which only contained file2.txt and file3.txt):
$ rm -fr somefiles
$ unzip -l somefiles.zip
Archive: somefiles.zip
Length Date Time Name
--------- ---------- ----- ----
0 2023-10-04 16:06 somefiles/
0 2023-10-04 16:05 somefiles/file1.txt
0 2023-10-04 16:06 somefiles/file2.txt
0 2023-10-04 16:06 somefiles/file3.txt
--------- -------
0 4 files
I did not see that coming! The command zip -r somefiles.zip somefiles/ doesn't create a fresh new .zip file based on recursively walking the somefiles directory. It does an append by default!
The solution is easy. Right before the zip -r somefiles.zip somefiles command, do a rm somefiles.zip.
Introducing hylite - a Node code-syntax-to-HTML highlighter written in Bun
October 3, 2023
0 comments Node, Bun, JavaScript
hylite is a command line tool for syntax highlight code into HTML. You feed it a file or some snippet of code (plus what language it is) and it returns a string of HTML.
Suppose you have:
❯ cat example.py
# This is example.py
def hello():
return "world"
When you run this through hylite you get:
❯ npx hylite example.py
<span class="hljs-keyword">def</span> <span class="hljs-title function_">hello</span>():
<span class="hljs-keyword">return</span> <span class="hljs-string">"world"</span>
Now, if installed with the necessary CSS, it can finally render this:
# This is example.py
def hello():
return "world"
(Note: At the time of writing this, npx hylite --list-css or npx hylite --css don't work unless you've git clone the github.com/peterbe/hylite repo)
How I use it
This originated because I loved how highlight.js works. It supports numerous languages, can even guess the language, is fast as heck, and the HTML output is compact.
Originally, my personal website, whose backend is in Python/Django, was using Pygments to do the syntax highlighting. The problem with that is it doesn't support JSX (or TSX). For example:
export function Bell({ color }: {color: string}) {
return <div style={{ backgroundColor: color }}>Ding!</div>
}
The problem is that Python != Node so to call out to hylite I use a sub-process. At the moment, I can't use bunx or npx because that depends on $PATH and stuff that the server doesn't have. Here's how I call hylite from Python:
command = settings.HYLITE_COMMAND.split()
assert language
command.extend(["--language", language, "--wrapped"])
process = subprocess.Popen(
command,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
cwd=settings.HYLITE_DIRECTORY,
)
process.stdin.write(code)
output, error = process.communicate()
The settings are:
HYLITE_DIRECTORY = "/home/django/hylite"
HYLITE_COMMAND = "node dist/index.js"
How I built hylite
What's different about hylite compared to other JavaScript packages and CLIs like this is that the development requires Bun. It's lovely because it has a built-in test runner, TypeScript transpiler, and it's just so lovely fast at starting for anything you do with it.
In my current view, I see Bun as an equivalent of TypeScript. It's convenient when developing but once stripped away it's just good old JavaScript and you don't have to worry about compatibility.
So I use bun for manual testing like bun run src/index.ts < foo.go but when it comes time to ship, I run bun run build (which executes, with bun, the src/build.ts) which then builds a dist/index.js file which you can run with either node or bun anywhere.
By the way, the README as a section on Benchmarking. It concludes two things:
node dist/index.jshas the same performance asbun run dist/index.jsbunx hyliteis 7x times faster thannpx hylitebut it's bullcrap becausebunxdoesn't check the network if there's a new version (...until you restart your computer)
Shallow clone vs. deep clone, in Node, with benchmark
September 29, 2023
0 comments Node, JavaScript
A very common way to create a "copy" of an Object in JavaScript is to copy all things from one object into an empty one. Example:
const original = {foo: "Foo"}
const copy = Object.assign({}, original)
copy.foo = "Bar"
console.log([original.foo, copy.foo])
This outputs
[ 'Foo', 'Bar' ]
Obviously the problem with this is that it's a shallow copy, best demonstrated with an example:
const original = { names: ["Peter"] }
const copy = Object.assign({}, original)
copy.names.push("Tucker")
console.log([original.names, copy.names])
This outputs:
[ [ 'Peter', 'Tucker' ], [ 'Peter', 'Tucker' ] ]
which is arguably counter-intuitive. Especially since the variable was named "copy".
Generally, I think Object.assign({}, someThing) is often a red flag because if not today, maybe in some future the thing you're copying might have mutables within.
The "solution" is to use structuredClone which has been available since Node 16. Actually, it was introduced within minor releases of Node 16, so be a little bit careful if you're still on Node 16.
Same example:
const original = { names: ["Peter"] };
// const copy = Object.assign({}, original);
const copy = structuredClone(original);
copy.names.push("Tucker");
console.log([original.names, copy.names]);
This outputs:
[ [ 'Peter' ], [ 'Peter', 'Tucker' ] ]
Another deep copy solution is to turn the object into a string, using JSON.stringify and turn it back into a (deeply copied) object using JSON.parse. It works like structuredClone but full of caveats such as unpredictable precision loss on floating point numbers, and not to mention date objects ceasing to be date objects but instead becoming strings.
Benchmark
Given how much "better" structuredClone is in that it's more intuitive and therefore less dangerous for sneaky nested mutation bugs. Is it fast? Before even running a benchmark; no, structuredClone is slower than Object.assign({}, ...) because of course. It does more! Perhaps the question should be: how much slower is structuredClone? Here's my benchmark code:
import fs from "fs"
import assert from "assert"
import Benchmark from "benchmark"
const obj = JSON.parse(fs.readFileSync("package-lock.json", "utf8"))
function f1() {
const copy = Object.assign({}, obj)
copy.name = "else"
assert(copy.name !== obj.name)
}
function f2() {
const copy = structuredClone(obj)
copy.name = "else"
assert(copy.name !== obj.name)
}
function f3() {
const copy = JSON.parse(JSON.stringify(obj))
copy.name = "else"
assert(copy.name !== obj.name)
}
new Benchmark.Suite()
.add("f1", f1)
.add("f2", f2)
.add("f3", f3)
.on("cycle", (event) => {
console.log(String(event.target))
})
.on("complete", function () {
console.log("Fastest is " + this.filter("fastest").map("name"))
})
.run()
The results:
❯ node assign-or-clone.js f1 x 8,057,542 ops/sec ±0.84% (93 runs sampled) f2 x 37,245 ops/sec ±0.68% (94 runs sampled) f3 x 37,978 ops/sec ±0.85% (92 runs sampled) Fastest is f1
In other words, Object.assign({}, ...) is 200 times faster than structuredClone.
By the way, I re-ran the benchmark with a much smaller object (using the package.json instead of the package-lock.json) and then Object.assign({}, ...) is only 20 times faster.
Mind you! They're both ridiculously fast in the grand scheme of things.
If you do this...
for (let i = 0; i < 10; i++) {
console.time("f1")
f1()
console.timeEnd("f1")
console.time("f2")
f2()
console.timeEnd("f2")
console.time("f3")
f3()
console.timeEnd("f3")
}
the last bit of output of that is:
f1: 0.006ms f2: 0.06ms f3: 0.053ms
which means that it took 0.06 milliseconds for structuredClone to make a convenient deep copy of an object that is 5KB as a JSON string.
Conclusion
Yes Object.assign({}, ...) is ridiculously faster than structuredClone but structuredClone is a better choice.